drf源码分析
request对象
drf中的request其实是对请求的再次封装,其目的就是在原来的request对象基础中再进行封装一些drf中需要用到的值。
认证
在开发API过程中,有些功能需要登录才能访问,有些无需登录。drf中的认证组件主要就是用来实现此功能
简单的认证示例
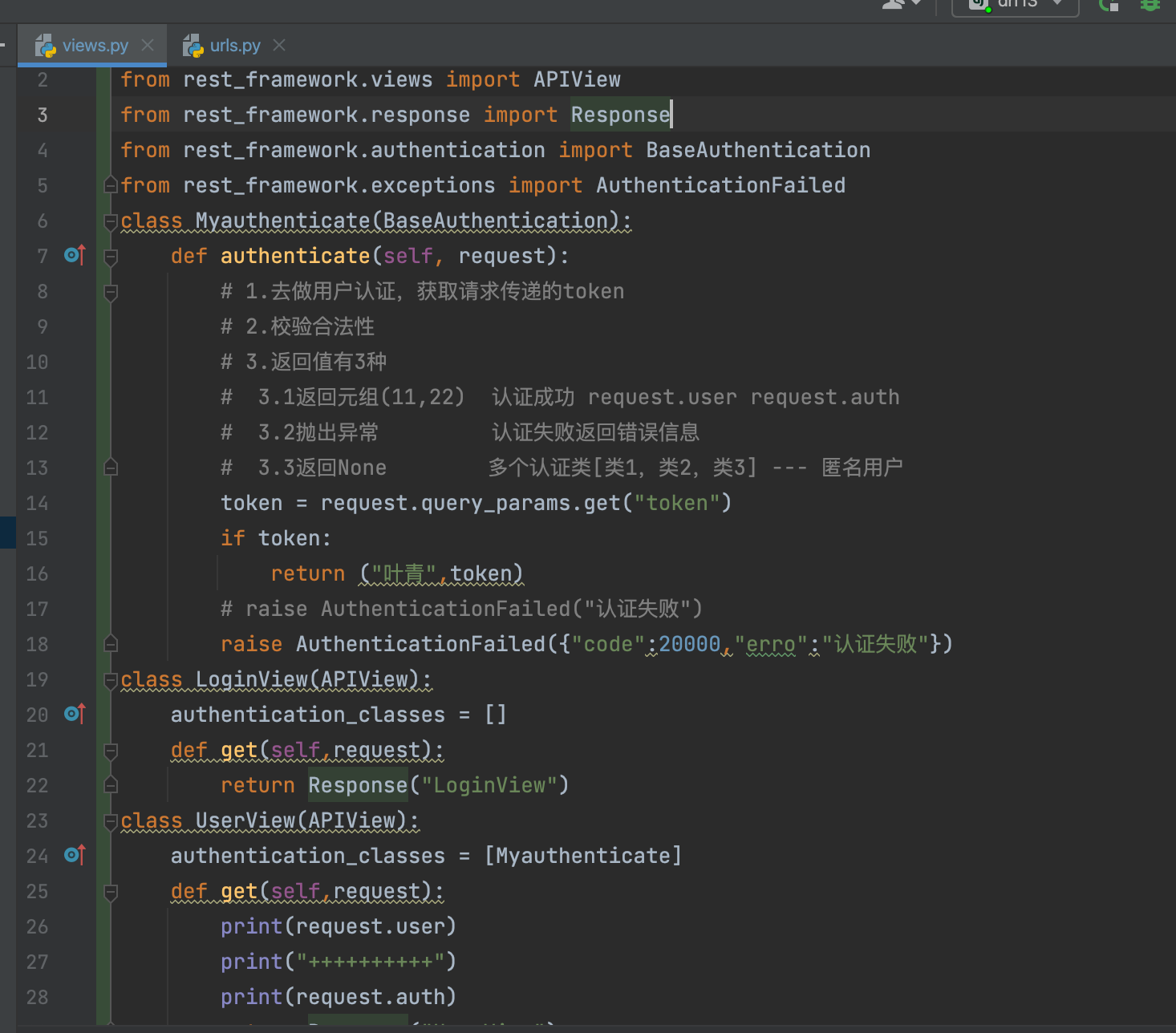
URL:
from django.contrib import admin
from django.urls import path
from api import views
urlpatterns = [
# path('admin/', admin.site.urls),
path('user/', views.UserView.as_view()),
path('login/', views.LoginView.as_view()),
path('order/', views.OrderView.as_view()),
]
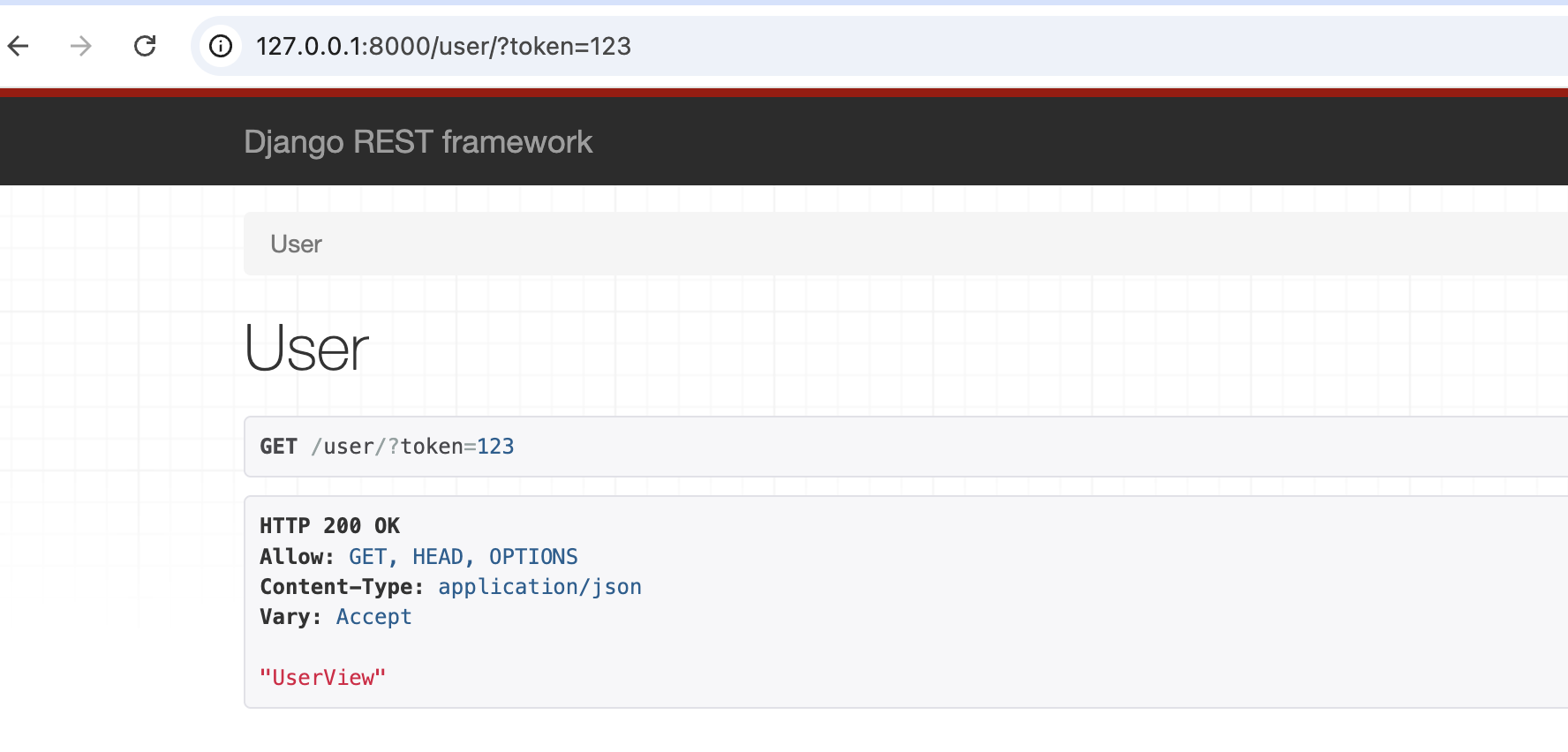
也可以全局配置比如100个api 有99个需要登录 一个不需要登录都可以访问的时候
认证单独写到一个地方:
from rest_framework.authentication import BaseAuthentication
from rest_framework.exceptions import AuthenticationFailed
class MyAuthentication(BaseAuthentication):
def authenticate(self, request):
token = request.query_params.get("token")
if not token:
# raise AuthenticationFailed("认证失败")
raise AuthenticationFailed({"code": 1002, "msg": "认证失败"})
return "武沛齐", token
def authenticate_header(self, request):
# return 'Basic realm="api"'
return 'Token'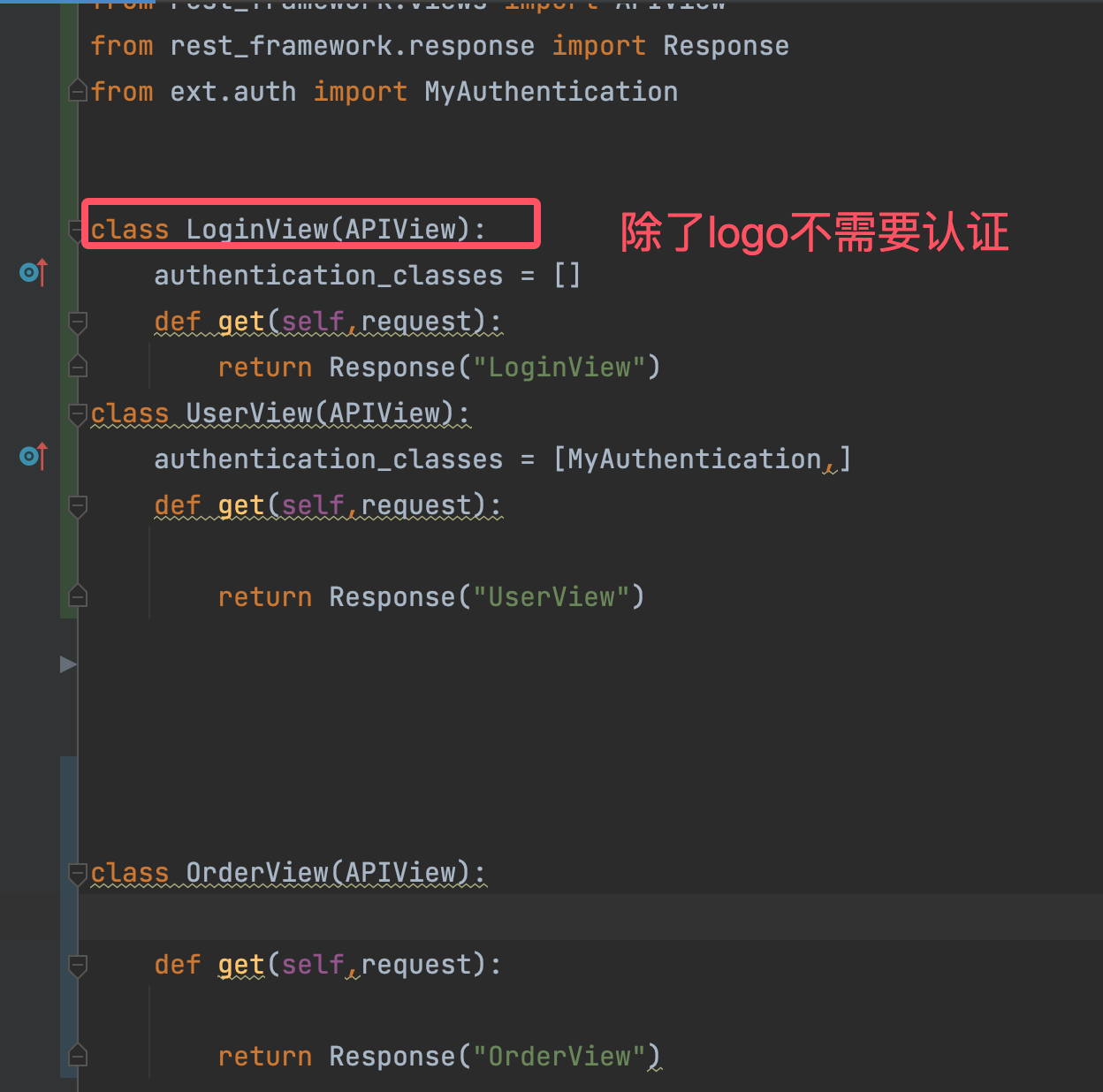
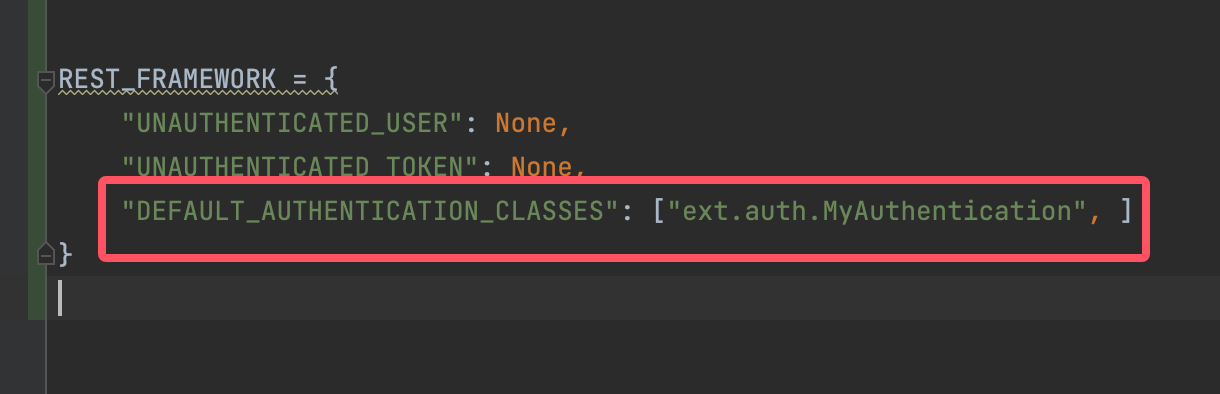
那么就是全局配置
权限
在drf开发中,如果有些接口必须同时满足:A条件、B条件、C条件。 有些接口只需要满足:B条件、C条件,此时就可以利用权限组件来编写这些条件。
且关系,默认支持:A条件 且 B条件 且 C条件,同时满足。
class PermissionA(BasePermission):
message = {"code": 1003, 'data': "无权访问"}
def has_permission(self, request, view):
if request.user.role == 2:
return True
return False
# 暂时先这么写
def has_object_permission(self, request, view, obj):
return True或关系,自定义(方便扩展)
class APIView(View):
def check_permissions(self, request):
"""
Check if the request should be permitted.
Raises an appropriate exception if the request is not permitted.
"""
for permission in self.get_permissions():
if not permission.has_permission(request, self):
self.permission_denied(
request,
message=getattr(permission, 'message', None),
code=getattr(permission, 'code', None)
)from rest_framework.views import APIView
class NbApiView(APIView):
def check_permissions(self, request):
no_permission_objects = []
for permission in self.get_permissions():
if permission.has_permission(request, self):
return
else:
no_permission_objects.append(permission)
else:
self.permission_denied(
request,
message=getattr(no_permission_objects[0], 'message', None),
code=getattr(no_permission_objects[0], 'code', None)
)
from rest_framework.permissions import BasePermission
class UserPermission(BasePermission):
message = {"status": False, 'msg': "无权访问1"}
def has_permission(self, request, view):
if request.user.role == 3:
return True
return False
class ManagerPermission(BasePermission):
message = {"status": False, 'msg': "无权访问2"}
def has_permission(self, request, view):
if request.user.role == 2:
return True
return False
class BossPermission(BasePermission):
message = {"status": False, 'msg': "无权访问2"}
def has_permission(self, request, view):
if request.user.role == 1:
return True
return False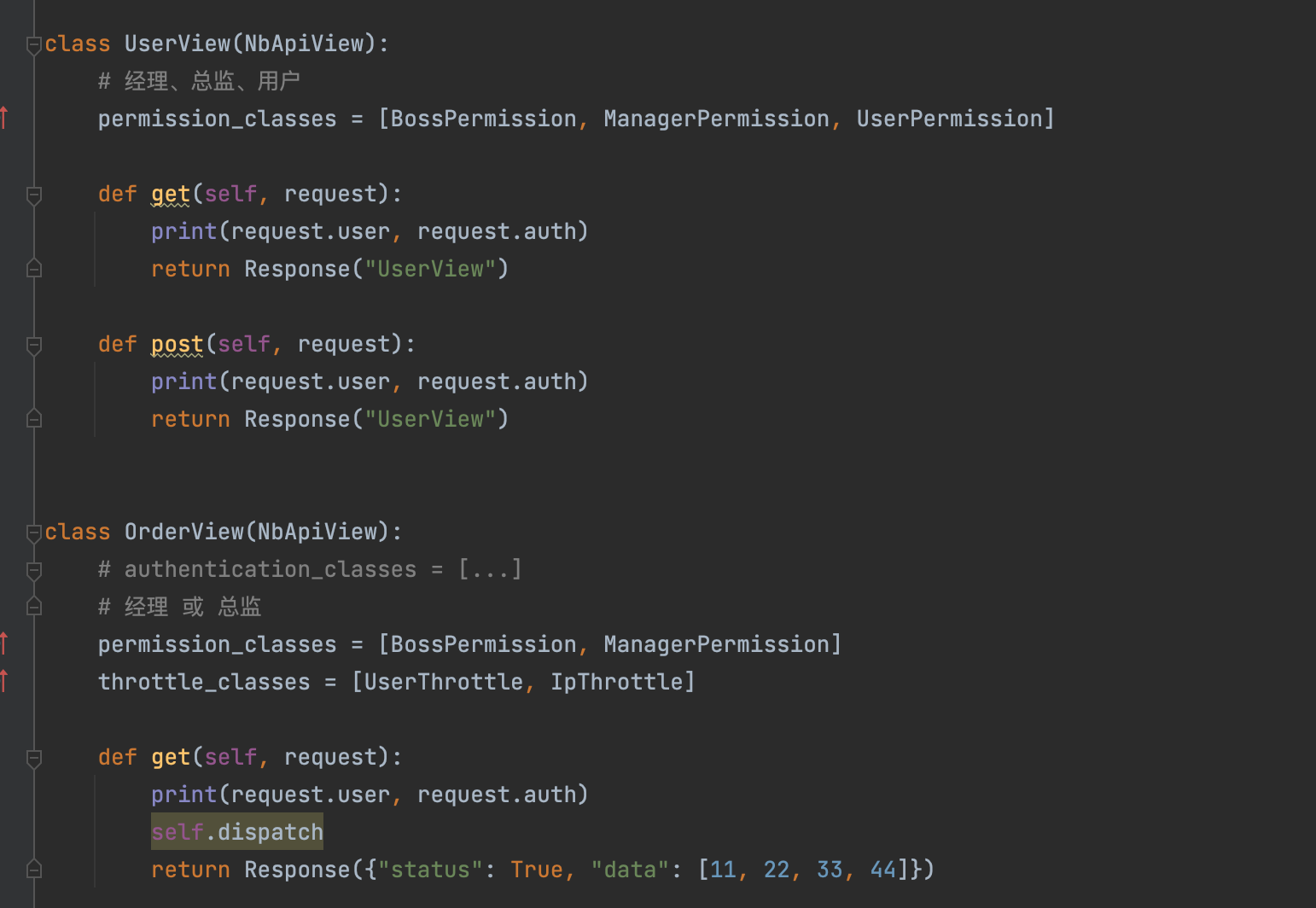
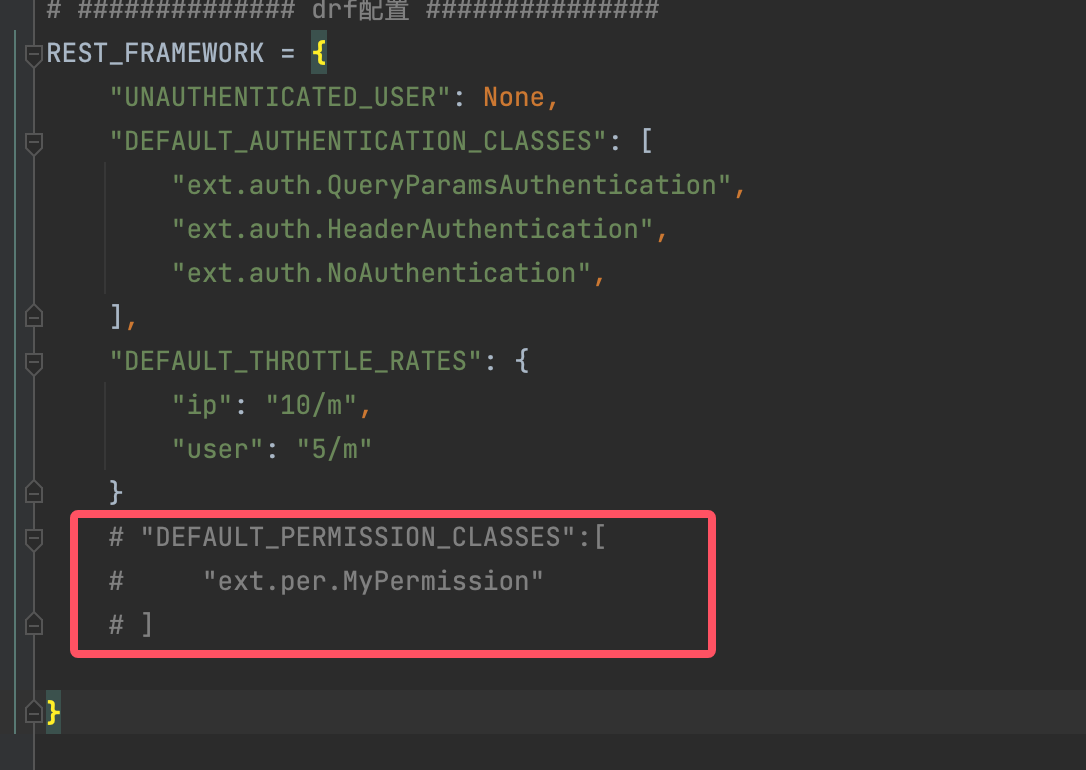
全局配置如图:
限流
限流,限制用户访问频率,例如:用户1分钟最多访问100次 或者 短信验证码一天每天可以发送50次, 防止盗刷。
对于匿名用户,使用用户IP作为唯一标识。
对于登录用户,使用用户ID或名称作为唯一标识。
安装redis pip3 install django-redis
redis的配置:
# settings.py
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"PASSWORD": "qwe123",
}
}
}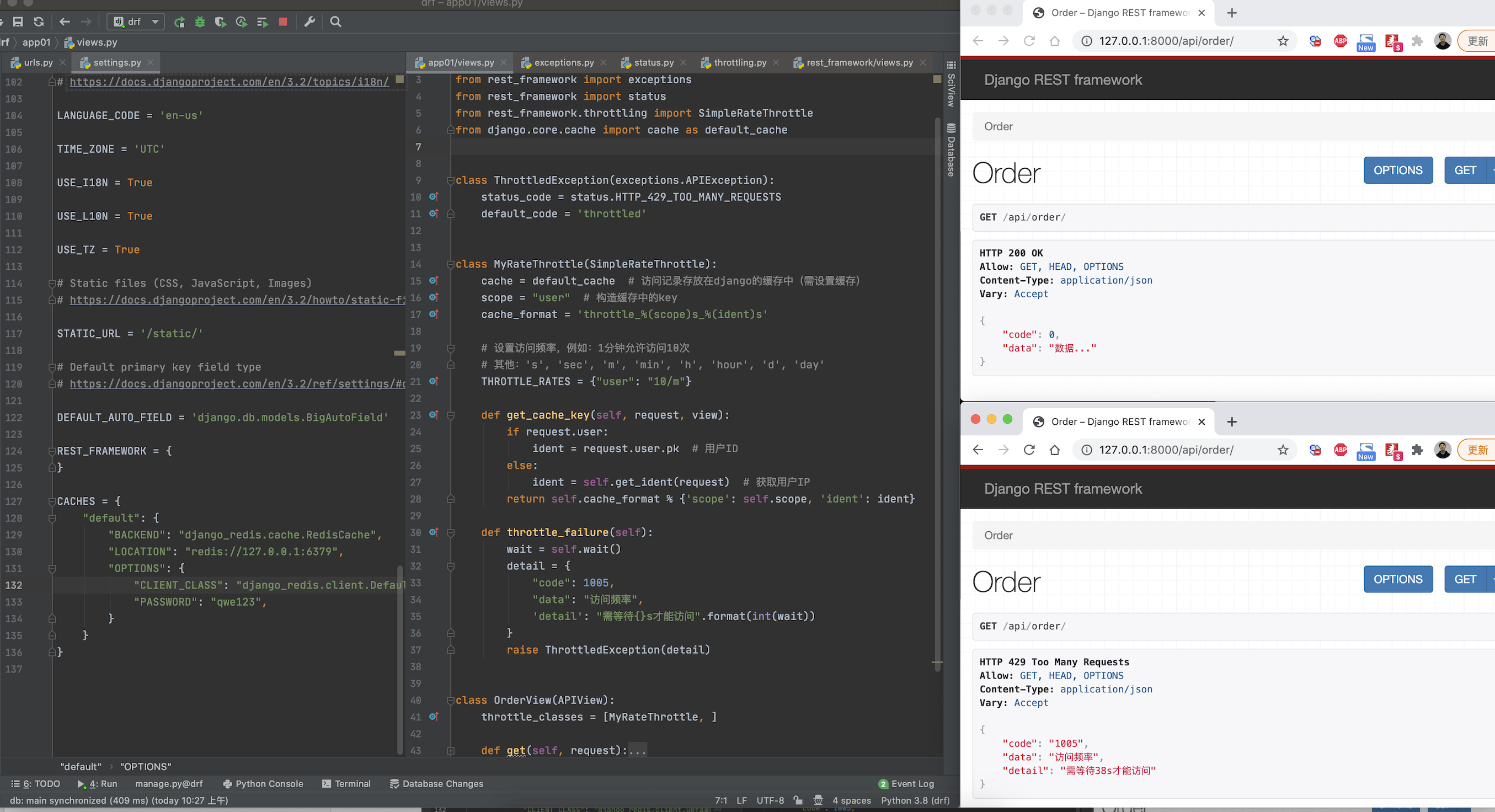
from django.urls import path, re_path
from app01 import views
urlpatterns = [
path('api/order/', views.OrderView.as_view()),
]# views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import exceptions
from rest_framework import status
from rest_framework.throttling import SimpleRateThrottle
from django.core.cache import cache as default_cache
class ThrottledException(exceptions.APIException):
status_code = status.HTTP_429_TOO_MANY_REQUESTS
default_code = 'throttled'
class MyRateThrottle(SimpleRateThrottle):
cache = default_cache # 访问记录存放在django的缓存中(需设置缓存)
scope = "user" # 构造缓存中的key
cache_format = 'throttle_%(scope)s_%(ident)s'
# 设置访问频率,例如:1分钟允许访问10次
# 其他:'s', 'sec', 'm', 'min', 'h', 'hour', 'd', 'day'
THROTTLE_RATES = {"user": "10/m"}
def get_cache_key(self, request, view):
if request.user:
ident = request.user.pk # 用户ID
else:
ident = self.get_ident(request) # 获取请求用户IP(去request中找请求头)
# throttle_u # throttle_user_11.11.11.11ser_2
return self.cache_format % {'scope': self.scope, 'ident': ident}
def throttle_failure(self):
wait = self.wait()
detail = {
"code": 1005,
"data": "访问频率限制",
'detail': "需等待{}s才能访问".format(int(wait))
}
raise ThrottledException(detail)
class OrderView(APIView):
throttle_classes = [MyRateThrottle, ]
def get(self, request):
return Response({"code": 0, "data": "数据..."})多个限流类
本质,每个限流的类中都有一个 allow_request 方法,此方法内部可以有三种情况:
返回True,表示当前限流类允许访问,继续执行后续的限流类。
返回False,表示当前限流类不允许访问,继续执行后续的限流类。所有的限流类执行完毕后,读取所有不允许的限流,并计算还需等待的时间。
抛出异常,表示当前限流类不允许访问,后续限流类不再执行。
全局配置:
REST_FRAMEWORK = {
"DEFAULT_THROTTLE_CLASSES":["xxx.xxx.xx.限流类", ],
"DEFAULT_THROTTLE_RATES": {
"user": "10/m",
"xx":"100/h"
}
}底层源码逻辑:

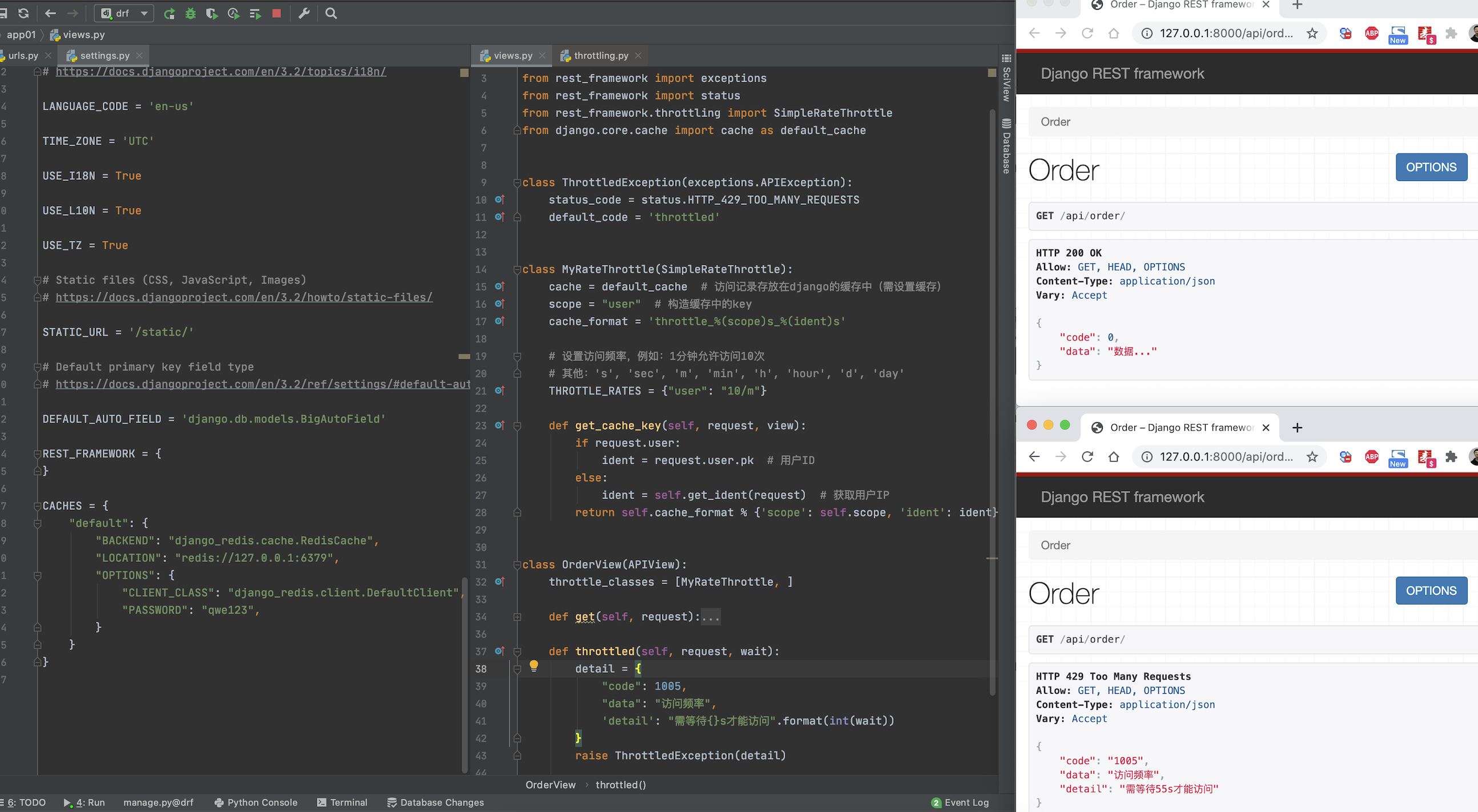
# throttle.py
from rest_framework.throttling import SimpleRateThrottle
from django.core.cache import cache as default_cache
class IpThrottle(SimpleRateThrottle):
scope = "ip"
cache = default_cache
def get_cache_key(self, request, view):
ident = self.get_ident(request) # 获取请求用户IP(去request中找请求头)
return self.cache_format % {'scope': self.scope, 'ident': ident}
class UserThrottle(SimpleRateThrottle):
scope = "user"
cache = default_cache
def get_cache_key(self, request, view):
ident = request.user.pk # 用户ID
return self.cache_format % {'scope': self.scope, 'ident': ident}
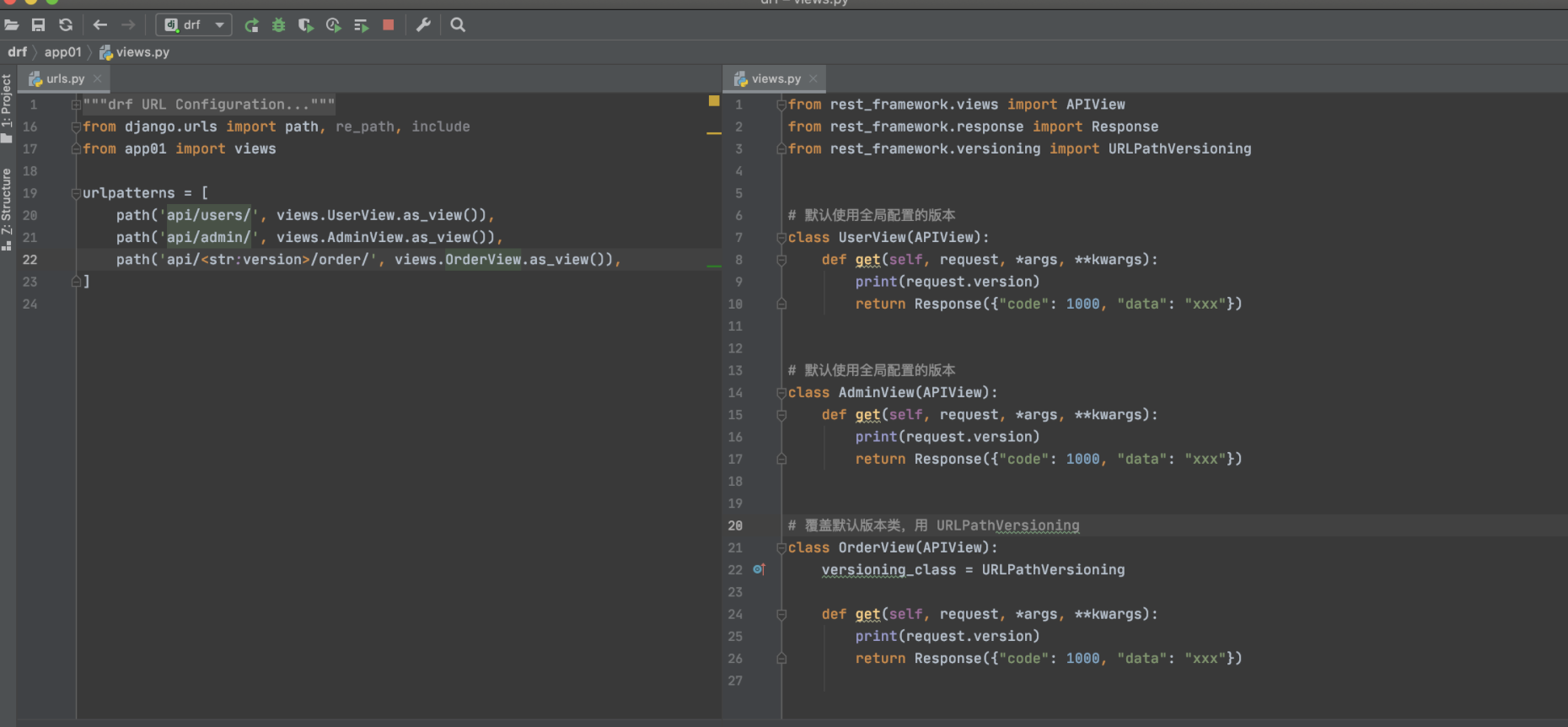
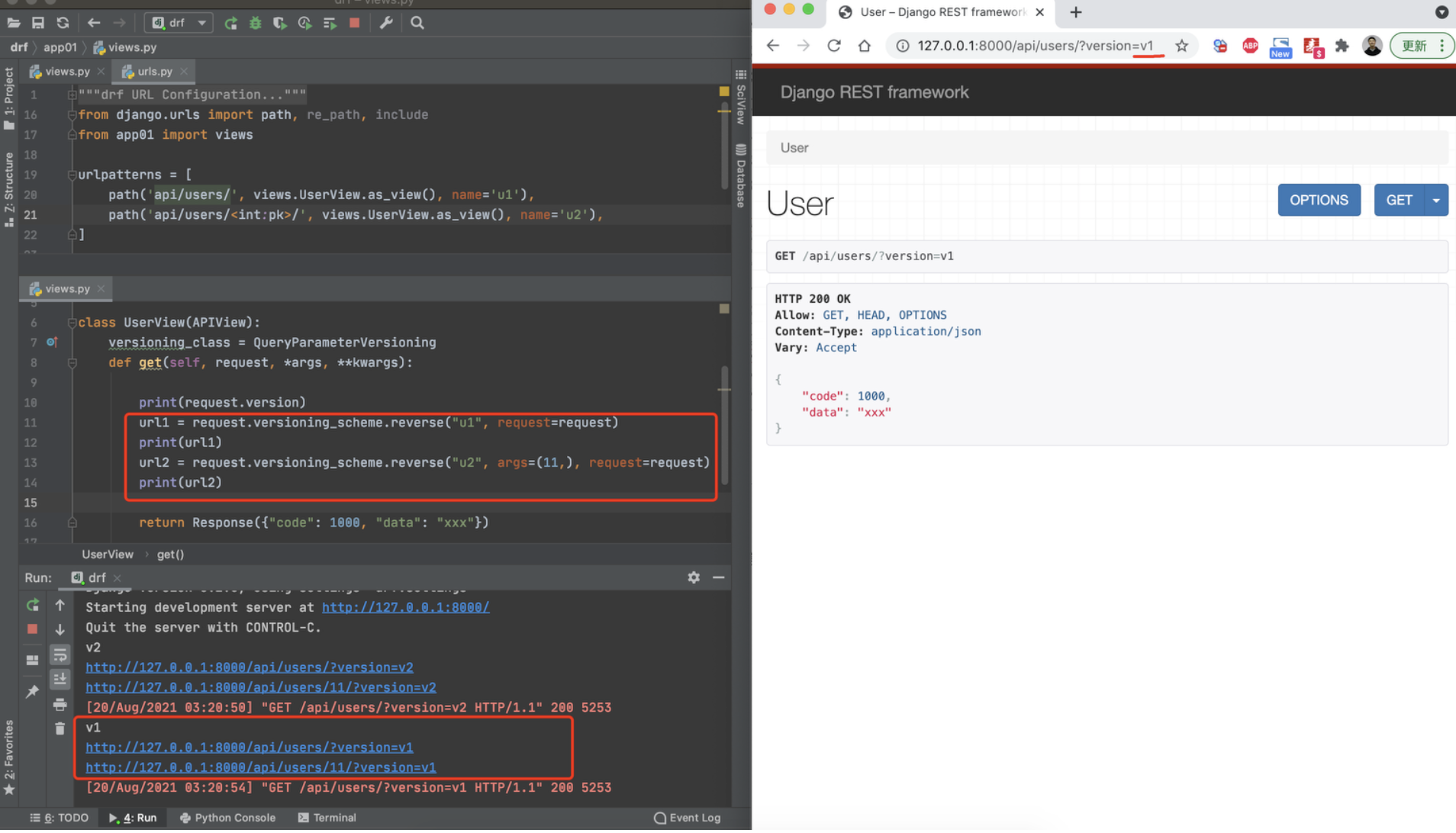
版本
# settings.py
REST_FRAMEWORK = {
"DEFAULT_VERSIONING_CLASS": "rest_framework.versioning.QueryParameterVersioning", # 处理版本的类的路径
"VERSION_PARAM": "version", # URL参数传参时的key,例如:xxxx?version=v1
"ALLOWED_VERSIONS": ["v1", "v2", "v3"], # 限制支持的版本,None表示无限制
"DEFAULT_VERSION": "v1", # 默认版本
}
解析器
序列化
一.核心类与继承结构
BaseSerializer
├── Serializer # 通用业务逻辑
│ ├── ListSerializer # 列表序列化器
│ └── ModelSerializer # 基于 Django ORM 的自动映射
└── SerializerMetaclass # 构造字段定义
BaseSerializer 定义了最基础的接口(
to_representation()、to_internal_value()、is_valid()、save()等),不包含字段声明与自动处理逻辑。Serializer 在 Base 基础上,实现了字段的收集、验证、读写转换,以及
create()/update()的默认调用流程。ModelSerializer 在 Serializer 基础上,自动根据 Django
Model的fields生成对应的Field,并重写了create()/update()以调用 ORM
二、字段收集与元类处理
1. SerializerMetaclass
源码过程:
class SerializerMetaclass(type):
def __new__(cls, name, bases, attrs):
# 1. 找到所有声明在类中的 Field 实例
declared_fields = [
(field_name, attrs.pop(field_name))
for field_name, obj in attrs.items()
if isinstance(obj, Field)
]
# 2. 保留声明顺序
declared_fields.sort(key=lambda x: x[1]._creation_counter)
# 3. 将它们放到类属性 _declared_fields
attrs['_declared_fields'] = OrderedDict(declared_fields)
return super().__new__(cls, name, bases, attrs)attrs 是什么?在 metaclass 的 __new__(cls, name, bases, attrs) 中,attrs 是一个 字典,包含了你在类体里写的所有名字和值。例如:
class MySerializer(Serializer):
foo = serializers.CharField(max_length=10)
bar = serializers.IntegerField()
baz = 123 # 不是 Field
此时,进入元类时的 attrs 大致是:
{
'__module__': '...',
'foo': <CharField instance at 0x...>,
'bar': <IntegerField instance at 0x...>,
'baz': 123,
'__doc__': None,
}
2. 为什么用 list(attrs.items())?
如果你直接写 for field_name, obj in attrs.items():,然后在循环体里做 attrs.pop(field_name),会因为“边遍历边改字典”而报错。
把它包一层 list(),就先把 (key, value) 对统统复制到一个列表里,后续再安全地对原字典 attrs 做 pop。
3. if isinstance(obj, Field)Field 是 DRF 定义的所有字段类型的基类(CharField, IntegerField, DateField……都继承自它)。这一句相当于“只要它是我们自己声明的序列化字段,就保留;否则忽略(比如普通属性 baz 就跳过)”。
4. attrs.pop(field_name)
作用一:从
attrs(类属性字典)里删除这个键——这样之后生成的类就不会再把它当成普通属性,而是让元类专门管理。作用二:
pop会返回被删除的值(也就是Field实例)。我们要把这个实例和它对应的名字一起收集起来。
5.最终得到的 fields 列表
以我们 MySerializer 为例,执行完毕后:
fields 变成
[
('foo', <CharField instance>),
('bar', <IntegerField instance>)
]
而 attrs 里剩下
{
'__module__': '…',
'baz': 123,
'__doc__': None,
}
之后,元类会对 fields 列表按声明顺序(利用每个 Field 实例内部的 _creation_counter)进行排序,然后把它存进类属性 _declared_fields,以供后续构造实例时使用。
用更“展开”的写法来看
如果把列表推导式改写成等价的循环,逻辑更清晰:
declared_fields = []
# 先把 attrs.items() 冻结成列表
for field_name, attr_value in list(attrs.items()):
# 只处理 DRF 的 Field 对象
if isinstance(attr_value, Field):
# 从 attrs 中删除这个属性,并获取它的实例
popped_field = attrs.pop(field_name)
# 记录下来
declared_fields.append((field_name, popped_field))
# 按 _creation_counter 排序以保持源代码中定义的顺序
declared_fields.sort(key=lambda kv: kv[1]._creation_counter)
# 最终附给这个 Serializer 类
attrs['_declared_fields'] = OrderedDict(declared_fields)
小结
目的:把你在类里写的
foo = CharField()、bar = IntegerField()等字段摘出来,后面实例化时才会创建self.fields['foo']、self.fields['bar'],并参与验证与输出。关键点:
用
list(attrs.items())避免遍历时改字典报错isinstance(obj, Field)过滤出真正的“序列化字段”attrs.pop(...)同时“挖出”并删除原来的类属性最终得到一个
[(name, Field实例), …]的列表,按定义顺序排序后存入_declared_fields
扫描:在创建
Serializer子类时,元类会遍历attrs,找出所有isinstance(obj, Field)的属性(如CharField、DateField等)
弹出:用
attrs.pop把它们从类定义里移除,避免实例间冲突排序:按
Field._creation_counter(声明时自增)保证源代码中的字段顺序存储:放进
_declared_fields,后续初始化时据此生成实例的self.fields
当你这样定义一个序列化器:
class BookSerializer(serializers.Serializer):
title = serializers.CharField(max_length=100)
published = serializers.DateField()
元类(
SerializerMetaclass) 会在类创建时,遍历类属性,找出所有Field实例(如CharField、DateField),并把它们按定义顺序收集到cls._declared_fields。然后在最终类上,将这些声明字段注入到
cls().fields,并移除类属性,避免实例间冲突
三、反序列化(解析并验证输入数据)流程
当你在视图中调用:
serializer = BookSerializer(data=request.data)
if serializer.is_valid():
validated = serializer.validated_data
实际发生了:
1.初始化
def __init__(self, *args, **kwargs):
self.initial_data = kwargs.pop('data', None)
self.partial = kwargs.pop('partial', False)
self.instance = kwargs.pop('instance', None)
# 收集 fields(包含声明的 & 额外添加的)
self.fields = self.get_fields()
2.调用 .is_valid()
def is_valid(self, raise_exception=False):
self._validated_data = {}
self._errors = {}
# run_validation 会遍历每个字段做验证
for field_name, field in self.fields.items():
raw_value = self.initial_data.get(field_name, empty)
try:
validated = field.run_validation(raw_value)
self._validated_data[field_name] = validated
except ValidationError as exc:
self._errors[field_name] = exc.detail
self._errors = ErrorDict(self._errors)
if self._errors and raise_exception:
raise ValidationError(self._errors)
return not bool(self._errors)
field.run_validation():先调用to_internal_value()(类型转换、必填检查等),再调用字段自带的校验器(如长度、格式)。把所有字段验证通过的数据收集到
self.validated_data,错误信息收集到self.errors。
3.保存数据
调用 serializer.save() 时,如果在实例化时传入了 instance,则走 update(),否则走 create():
def save(self, **kwargs):
assert self.is_valid(), "Save 前必须调用 is_valid()"
validated = {**self.validated_data, **kwargs}
if self.instance is not None:
return self.update(self.instance, validated)
return self.create(validated)
默认
create()/update()在非 ModelSerializer 中只是抛错,提示你自定义。ModelSerializer 会根据 Meta.model,自动调用
Model.objects.create(**validated)或instance.save()。
四、序列化(转输出)流程
当你有一个 Python 对象(或 QuerySet)要转成 JSON 时,调用:
serializer = BookSerializer(book_instance)
data = serializer.data
实际执行:
@property
def data(self):
# 如果是列表(ListSerializer),则对每个元素序列化
# 否则调用 to_representation(self.instance)
return self.to_representation(self.instance)
to_representation()
def to_representation(self, instance):
ret = OrderedDict()
for field_name, field in self.fields.items():
attribute = field.get_attribute(instance)
ret[field_name] = field.to_representation(attribute)
return ret
field.get_attribute():获取实例上对应的值,支持嵌套属性(source='author.name')。field.to_representation():把 Python 值(如date、decimal)转换成可 JSON 化的类型(字符串、数值、列表、字典)。
五、ModelSerializer 的扩展
在 ModelSerializer 中,除了继承上述流程,还会:
1.自动生成字段
class ModelSerializer(Serializer):
def get_fields(self):
# 根据 Meta.model 和 Meta.fields/Meta.exclude
# 自动为每个 Model 字段创建对应的 DRF Field
2.自动实现 create/update
def create(self, validated_data):
return self.Meta.model.objects.create(**validated_data)
def update(self, instance, validated_data):
for attr, value in validated_data.items():
setattr(instance, attr, value)
instance.save()
return instance
六、整体调用顺序图
┌────────────┐ ┌─────────────┐
│ Serializer │ --init→ │ collect │
│ .__init__()│ │ fields │
└────────────┘ └─────────────┘
│ │
│ is_valid() │ data
▼ ▼
┌────────────┐ ┌─────────────┐
│ Serializer │ │ Serializer │
│ .is_valid()│ │ .data │
└────────────┘ └─────────────┘
│ │
│ run_validation │ to_representation
▼ ▼
┌────────────┐ ┌─────────────┐
│ Field │ │ Field │
│ .run_…() │ │ .to_repr() │
└────────────┘ └─────────────┘
评论